Implementing Background Blur on Android @ Nextcloud
The problem:
Most video conferencing apps now have a background blur feature, which is great for privacy and reducing distractions. Think Zoom, Google Meet, Nextcloud Talk, etc. However, at Nextcloud this feature was present on iOS and Web, but not on Android. Unlike iOS, background blurring is not built into the Android SDK. So I had to figure out how to implement it manually. Implementing this feature on Android can be challenging due to the platform's limitations and the need for real-time processing. Since at Nextcloud we use WebRTC for video calls, I had to find a way to integrate background blurring into the WebRTC video stream. In addition, I had to find a way to segment the user from the background in real-time and blur the background which is a non-trivial task. Finally, I had to ensure that the implementation was efficient and did not introduce significant latency or degrade video quality, while also being maintainable for future developers to understand, extend, and debug.
The Research:
For segmenting the background/foreground, I decided to use Media Pipe, an open source framework AI/ML with first class support for Android. As for the model itself, I used the Selfie Segmentation model from Google, the light weight (250 KB), on device image segmentation model is available for commercial use (Apache License V2) here is more info about the model. As for blurring the background, I used OpenCV, a popular computer vision library with Android support. It supports Guassian blur, which is a common technique for blurring images, due to it's kernel being able to be split into two 1D kernels, making it very efficient for parallelization. OpenCV uses JNI (Java Native Interface) under the hood to call native C++ code to make use of true parallelization, low latency, and advanced compiler and hardware specfic optimizations, so I don't have to.
// Computer Vision - for background effects during video calls
implementation('com.google.mediapipe:tasks-vision:0.10.26')
implementation('org.opencv:opencv:4.12.0')
A little background knowledge is needed about image file formats as well. Typically, AI models like these rely on RGB images, which are 3 channel images, where each pixel is represented by 3 values (Red, Green, Blue). However, WebRTC uses YUV images, which are 3 channel images as well, which means three values are used to represent 1 pixel. But the channels are Y (luminance), U (chrominance blue), and V (chrominance red). The Y channel is a grayscale image, while the U and V channels are used to represent color information. The YUV format is more efficient for video compression and transmission, which is why cameras natively support it, but to use it with AI models, we need to convert it to RGB format.
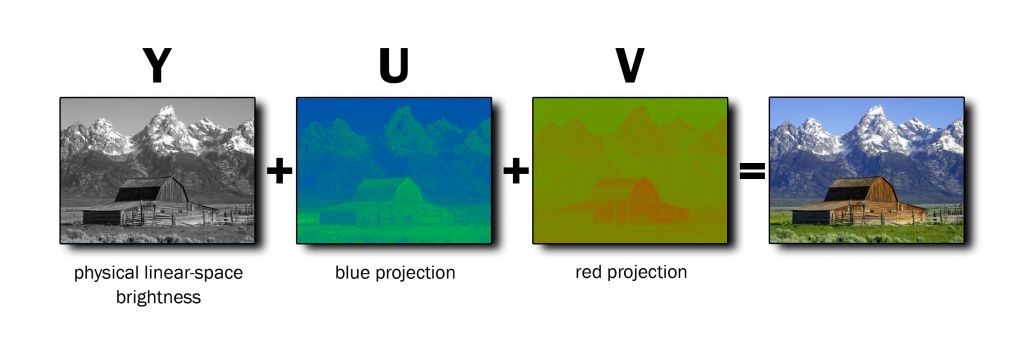

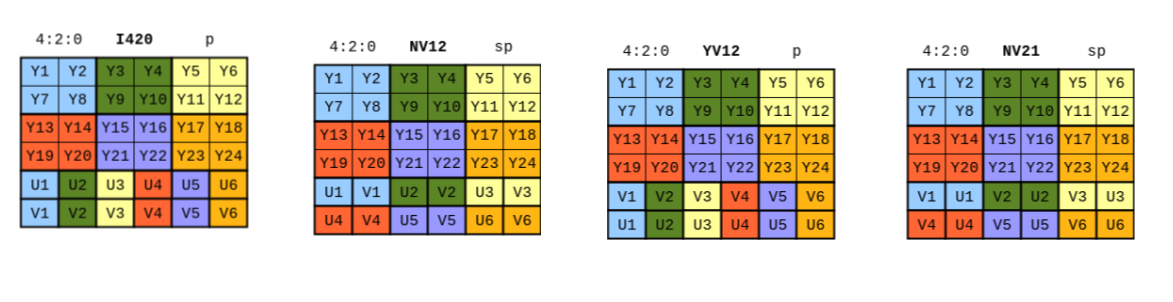
There are also different types of ways to format YUV files, depending on the underlying implementation. Thankfully, WebRTC provides a helper class YUVHelper to abstract away the conversion logic. But it can be helpful to understand that at the end of the day, it's still just a 2d array.
The Implementation:
I created/edited 13 files, but here are the 2 main files of value worth discussing. Listed
-
Code found hereBackgroundBlurFrameProcessoran implementation ofVideoProcessorwhich is an interface that WebRTC provides to perform operations on camera frames, andImageSegmentationHelper.SegmenterListener, which is a small interface I wrote to handle asynchronous passing of camera frames from MediaPipe (You can actually handle it synchronously too, since the VideoProcessor operates on it's own thread, but this is cleaner) -
Code found hereImageSegmentationHelperan edited version of google's. Basically a wrapper over MediaPipe'sImageSegmenterwhich uses the on device AI Model to segment images between the foreground and background.
The Result:
Mask: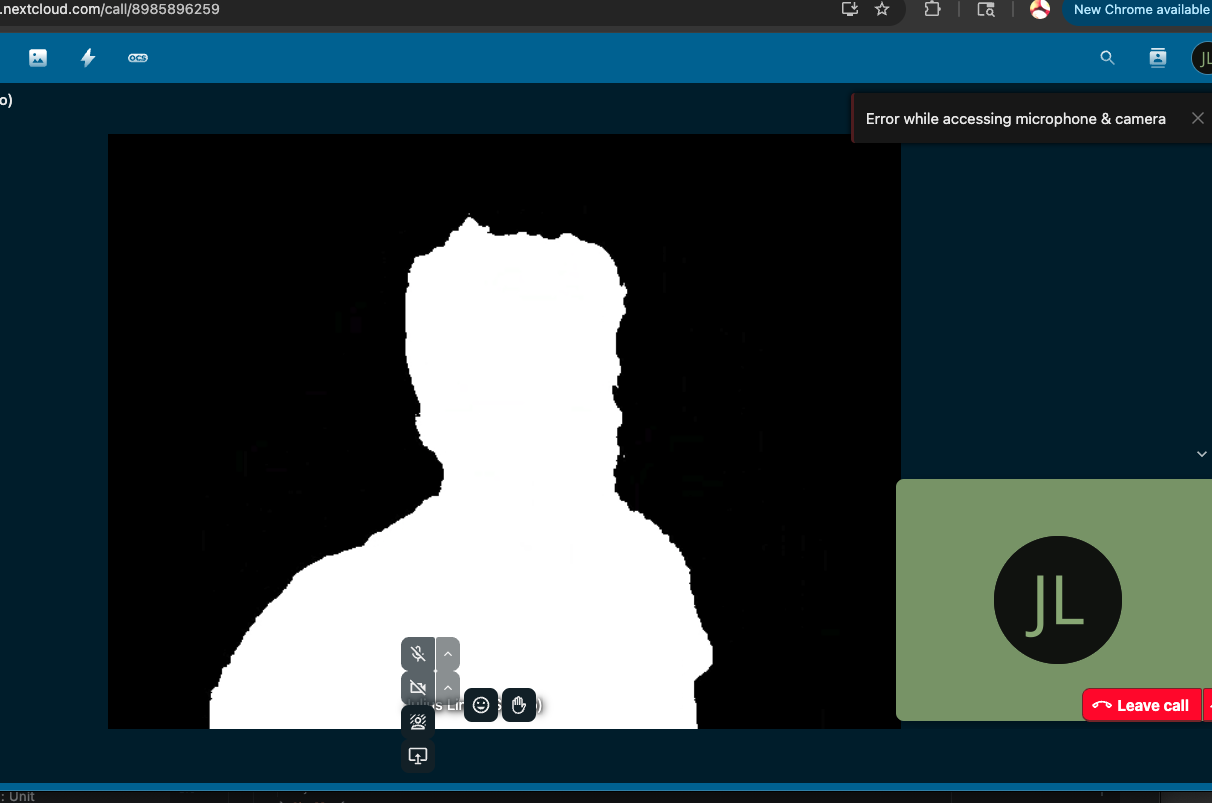
|
Post Process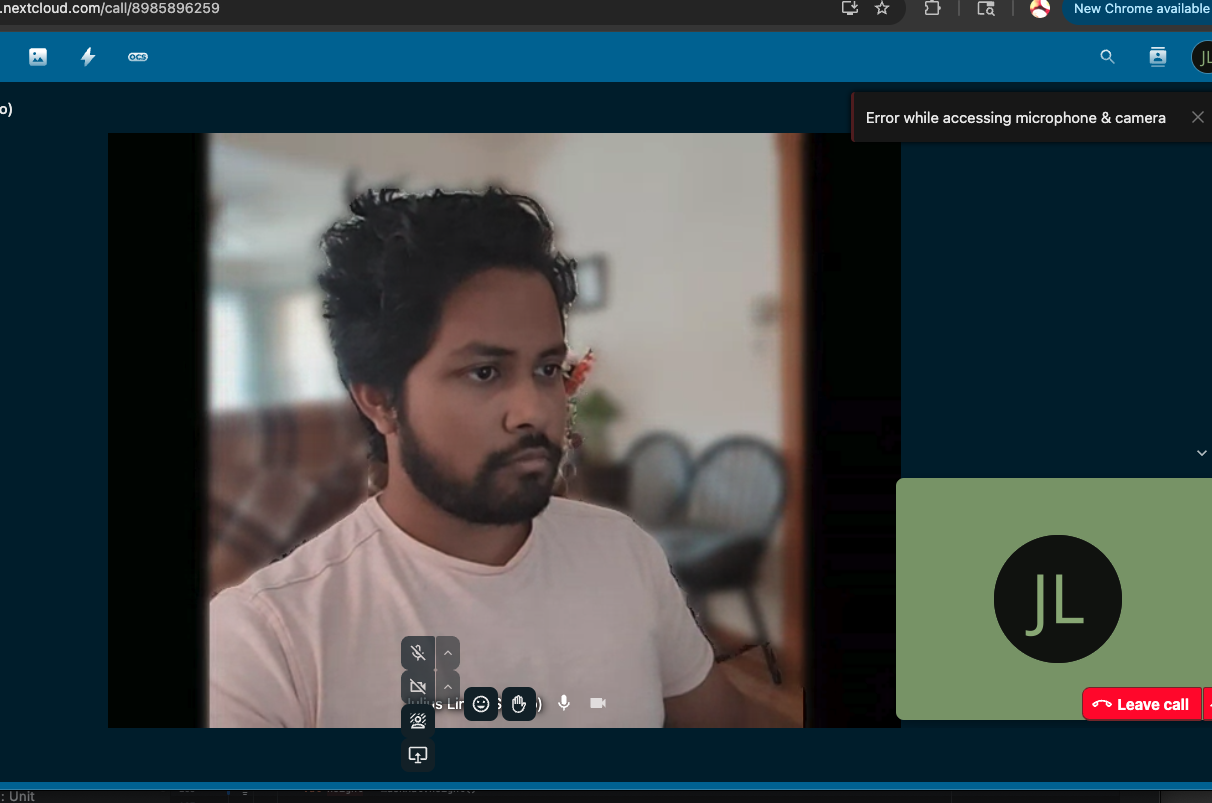
|
Notes
The model runs at ~19 FPS on a Pixel 7a, which is decent for real-time video processing. There can be distortion effects on older devices, but it works well on modern devices. The blurring effect is good, but not perfect. There are some artifacts around the edges of the user, especially when the user is moving quickly. This is likely due to the limitations of the segmentation model. The performance can be improved by offloading work to the GPU, but this can lead to unmaintable code. I opted to keep the implementation simple and maintainable by using CPU only processing. But it's worth a look in the future.